Para trabajar con datos, lo esencial es disponer de datos. A veces esa información se encuentra estructurada y, en otras ocasiones, está desestructurada. Hoy en día existen numerosas herramientas o procesos por los cuáles un desarrollador puede extraer datos de formatos complejos como un PDF o bien de una o varias páginas web, lo que se conoce como web scraping. El objetivo es tener los datos para poder visualizar y entender.
Web scraping se podría definir como la técnica por la que un equipo de desarrolladores es capaz de rascar, escrapear o liberar datos de páginas web de gobiernos, instituciones públicas u organizaciones para acceder a datos privados o públicos que puedan ser publicados o distribuidos en formato abierto. El problema es que la mayoría de los datos de interés están en formatos no reutilizables y poco transparentes como un PDF, por ejemplo.
Para acceder y distribuir este tipo de información existe una gran cantidad de herramientas o procesos mediante el uso de lenguajes de programación. Esta es una guía de uso de los principales métodos de extracción de datos.
Herramientas de web scraping (rascado de datos)
● Fórmula ImportHTML
Dentro de las aplicaciones de Google, el gran buscador desarrolló su propio Excel llamado Google Spreadsheet (las hojas de cálculo de Google). Esta herramienta dispone de casi todas las características de Microsoft Excel, pero además dispone de algunas funcionalidades añadidas gracias al contenido indexado en internet por el buscador: lectura de feeds RSS, cambios en páginas web o extracción de datos.
Todo esto es posible mediante el uso de fórmulas como ImportFeed, ImportHTML e ImportXML. Con la segunda de ellas, cualquier usuario puede extraer datos de tablas o listados de forma ordenada desde cualquier página web. Dependiendo de si es una tabla o una lista, el tipo de fórmula varia en uno de sus elementos. Dos ejemplos prácticos:
=ImportHTML(“url página web”, “table”, 2)
=ImportHTML(“url página web”, “list”, 2)
Cualquiera de estas fórmulas colocadas en la primera celda de Google Spreadsheet permite extraer la segunda tabla o lista de la url que el usuario coloque dentro de las dobles comillas. Es muy sencillo.
Table Capture es una extensión para el navegador Chrome, que proporciona a un usuario los datos de una web sin excesivos problemas. Saca la información contenida en una tabla en HTML de una página web a cualquier formato de tratamiento de datos como Google Spreadsheet, Excel o CSV. Algo similar a la fórmula ImportHTML.
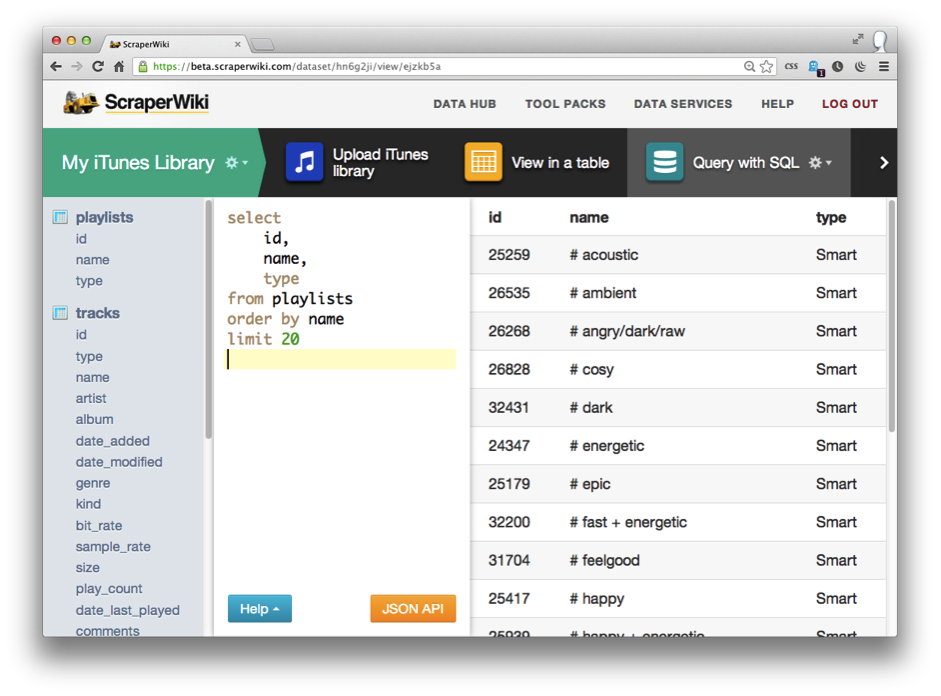
ScraperWiki es una herramienta perfecta para la extracción de datos dispuestos en tablas en un PDF. Es tan sencillo como cargar el archivo y exportar. Si el PDF tiene varias páginas y numerosas tablas, ScraperWiki ofrece una vista previa con todas las páginas y las distintas tablas y la posibilidad de descargar los datos de forma ordenada y separada.
Con ScraperWiki también se pueden limpiar los datos antes de ser exportados a un archivo Microsoft Excel. Esto es interesante porque, al añadir esos datos limpios a una herramienta de visualización, todo es más sencillo.
Tabula es una aplicación de escritorio para equipos Windows, Mac OSX y Linux, que proporciona a los desarrolladores e investigadores un método sencillo de extracción de datos desde un PDF a un archivo en formato CSV o Microsoft Excel para su modificación y visualización. Tabula es una herramienta muy utilizada en el periodismo de datos.
Los pasos a seguir para utilizar Tabula:
– Cargar un PDF con la tabla de datos que se quiere exportar.
– Seleccionar la tabla con toda la información.
– Seleccionar la opción de ‘Vista previa y extracción de datos’. Tabula escrapea los datos de la tabla y ofrece al usuario una vista previa de la información extraída para su comprobación.
– Pulsar el botón de ‘Exportar’.
– Los datos se exportan a un archivo Microsoft Excel o bien un archivo LibreOffice si no disponemos de Microsoft Office.
Import.io es una herramienta online gratuita, aunque también dispone de una versión de pago para empresas. Facilita la extracción estructurada de datos y su descarga en formato CSV o bien generar una API con la información. Los datos de la API se actualizan a medida que la información se modifica en el entorno de origen.
Import.io dispone de una aplicación de escritorio que cualquier usuario se puede descargar en su máquina Windows, Mac OSX o Linux. En esta aplicación, Import.io ofrece varios métodos de extracción de datos muy distintos: información contenida en una url, información en lenguaje HTML o XML, imágenes, valores numéricos, mapas… De todo.
Extracción de datos con Python
En BBVAOpen4U ya hemos visto qué es y cómo funciona Python para el desarrollo de proyectos digitales o el uso de librerías para visualización de datos, pero es la primera vez que se menciona una de sus funcionalidades más interesantes y profesionales: la extracción de datos no estructurados. También existen numerosas librerías en este lenguaje para el acceso a datos.
BeautifulSoup es una librería en Python que sirve para la extracción sencilla de datos concretos de una página web en HTML sin excesiva programación. Es lo que técnicamente recibe el nombre de parsear HTML. Una de las ventajas de esta biblioteca en Python es que todos los documentos salientes de la extracción de datos lo hacen en UTF-8, lo cual es bastante interesante porque el problema típico de las codificaciones queda totalmente resuelto.
Otras de las características potentes de BeautifulSoup es que utiliza analizadores de Python como lxml o html5lib, que permiten rastrear páginas web con estructura de árbol. Gracias a ellos, se puede recorrer cada ‘habitación’ de una web, abrirla, extraer su información e imprimirla.
Scrapy es un marco de desarrollo de código abierto para la extracción de datos con Python. Este framework permite a los desarrolladores la programación de arañas que sirven para rastrear y extraer información concreta de una o varias páginas web a la vez. El mecanismo que utiliza recibe el nombre de selectores, aunque también se pueden utilizar librerías en Python como BeautifulSoup o lxml.
El leasing puede ser el impulso que necesitan las empresas para arrancar, abonando cuotas predecibles para usar bienes que, además, podrán adquirir luego descontando esos pagos. Las empresas, desde los autónomos hasta las grandes empresas pasando por las pymes, necesitan soluciones de financiación que se adapten a sus necesidades. El leasing es una fórmula que […]
Una API es el mecanismo más útil para conectar dos softwares entre sí para el intercambio de mensajes o datos en formato estándar como XML o JSON. Así es como se convierte en un instrumento para buscar ingresos, abrirse al talento, innovar y automatizar procesos.
El ecosistema de Embedded Finance (EF) y Bank-as-a-Service (BaaS) está en plena expansión y definición de los roles de nuevos actores que entran al ecosistema, y que persiguen cubrir nichos o crear nuevos servicios. ¿Cómo evolucionará el sector de Embedded Finance y Bank-as-a-Service? José Luis Navarro Llorens es el responsable de Estrategia Open Banking en […]
Por favor, si no lo encuentras, recuerda revisar la sección de correo no deseado
×
El correo electrónico con tu ebook está en camino
Te hemos enviado dos mensajes. Uno con el ebook solicitado y otro para confirmar tu correo electrónico y empezar a recibir la newsletter de BBVA API_Market
×
TRATAMIENTO DE DATOS PERSONALES
¿Quién es el Responsable del tratamiento de tus datos personales?
Banco Bilbao Vizcaya Argentaria, S.A. (“BBVA”), con domicilio social en Plaza de San Nicolás 4, 48005, Bilbao, España, C.I.F. A-48265169 Dirección de correo electrónico: contact.bbvaapimarket@bbva.com
¿Para qué y por qué utilizamos tus datos personales?
Para aquellas de las siguientes actividades para la que nos prestes tu consentimiento marcando la casilla correspondiente:
para la ejecución y gestión de tu solicitud, en concreto, recibir la newsletter de BBVA API_Market por medios electrónicos;
para enviarte comunicaciones comerciales, eventos y encuestas relativas a BBVA API_Market a la dirección de correo electrónico que nos hayas facilitado.
¿Durante cuánto tiempo conservaremos tus datos?
Conservaremos tus datos hasta que te des de baja para dejar de recibir nuestra newsletter o, en su caso, las comunicaciones comerciales, eventos y encuestas a las que te hayas suscrito. Tanto si te das de baja como si BBVA decide finalizar el servicio, tus datos serán eliminados.
¿Cómo puedo darme de baja para dejar de recibir la newsletter y/o comunicaciones de BBVA API_Market?
Puedes darte de baja en cualquier momento y sin necesidad de indicarnos ninguna justificación, remitiendo un correo electrónico a la siguiente dirección: contact.bbvaapimarket@bbva.com
¿A quién comunicaremos tus datos?
No cederemos tus datos personales a terceros, salvo que estemos obligados por una ley o que tú lo consientas previamente.
¿Cuáles son tus derechos cuando nos facilitas tus datos?
Consultar los datos personales que se incluyan en los ficheros de BBVA (derecho de acceso)
Solicitar la modificación de tus datos personales (derecho de rectificación)
Solicitar que no se traten tus datos personales (derecho de oposición)
Solicitar la supresión de tus datos personales (derecho de supresión)
Limitar el tratamiento de tus datos personales en los supuestos permitidos (limitación del tratamiento)
Recibir así como a transmitir a otra entidad, en formato electrónico, los datos personales que nos hayas facilitado y aquellos que se han obtenido de tu relación con BBVA (derecho de portabilidad)
Te responsabilizas de la veracidad de los datos personales que facilitas a BBVA y de mantenerlos debidamente actualizados.
Si consideras que no hemos tratado tus datos personales de acuerdo con la normativa, puedes contactar con el Delegado de Protección de Datos en la dirección dpogrupobbva@bbva.com
Puedes encontrar más información en el documento “Política de Protección de Datos Personales” de esta página web.
×
TRATAMIENTO DE DATOS PERSONALES
¿Quién es el Responsable del tratamiento de tus datos personales?
Banco Bilbao Vizcaya Argentaria, S.A. (“BBVA”), con domicilio social en Plaza de San Nicolás 4, 48005, Bilbao, España, C.I.F. A-48265169 Dirección de correo electrónico:contact.bbvaapimarket@bbva.com
¿Para qué y por qué utilizamos tus datos personales?
Para la ejecución y gestión de tu solicitud, en concreto, descargar el e-book/s solicitado.
BBVA informa te informa de que, salvo que indiques tu oposición enviando un correo a la siguiente dirección:contact.bbvaapimarket@bbva.com, BBVA podrá enviarte comunicaciones comerciales, encuestas y eventos relativas a productos y/o servicios de BBVA API Market a través de medios electrónicos.
¿Durante cuánto tiempo conservaremos tus datos?
Conservaremos tus datos mientras sea necesario para la gestión de la solicitud, así como para el envío de comunicaciones comerciales, eventos y/o, encuestas. BBVAconservará tus datos hasta que te des de baja para dejar de recibir dichas comunicaciones o, en su caso, hasta que finalice el servicio.Después, destruiremos tus datos.
¿Cómo puedo darme de baja para dejar de recibir newsletters y/o comunicaciones de BBVA API Market?
Puedes darte de baja en cualquier momento y sin necesidad de indicarnos ninguna justificación, remitiendo un correo electrónico a la siguiente dirección:contact.bbvaapimarket@bbva.com
¿A quién comunicaremos tus datos?
No cederemos tus datos personales a terceros, salvo que estemos obligados por una ley o que tú lo consientas previamente.
¿Cuáles son tus derechos cuando nos facilitas tus datos?
Consultar los datos personales que se incluyan en los ficheros de BBVA (derecho de acceso)
Solicitar la modificación de tus datos personales (derecho de rectificación)
Solicitar que no se traten tus datos personales (derecho de oposición)
Solicitar la supresión de tus datos personales (derecho de supresión)
Limitar el tratamiento de tus datos personales en los supuestos permitidos (limitación del tratamiento)
Recibir así como a transmitir a otra entidad, en formato electrónico, los datos personales que nos hayas facilitado y aquellos que se han obtenido de tu relación con BBVA (derecho de portabilidad)
Puedes ejercitar ante BBVA los citados derechos a través de la siguiente dirección:contact.bbvaapimarket@bbva.com
Te responsabilizas de la veracidad de los datos personales que facilitas a BBVA y de mantenerlos debidamente actualizados.
Si consideras que no hemos tratado tus datos personales de acuerdo con la normativa, puedes contactar con el Delegado de Protección de Datos de BBVA en la dirección dpogrupobbva@bbva.com
Puedes encontrar más información en el documento “Política de Protección de Datos Personales ” de esta página web.
Banco Bilbao Vizcaya Argentaria, S.A. titular de este portal utiliza cookies y/o tecnologías similares propias y de terceros para fines técnicos, de personalización, analíticos, de publicidad comportamental o publicidad relacionada con tus preferencias sobre la base de un perfil elaborado a partir de tus hábitos de navegación (por ejemplo, páginas visitadas). Si deseas obtener información más detallada, consulta nuestra Política de Cookies.
Panel de configuración de cookies
Este es el configurador avanzado de cookies propias y de terceros. Aquí puedes modificar parámetros que afectarán directamente a tu experiencia de navegación en esta web.
Cookies técnicas (necesarias)
Estas cookies son importantes para darte acceso seguro a zonas con información personal o para reconocerte cuando inicias sesión.
Denominación
Titular
Duración
Finalidad
gobp.lang
BBVA
1 mes
Preferencia de idioma
aceptarCookies
BBVA
1 año
Configuración Cookies aceptadas
_abck
BBVA
1 año
Ayuda a protegerse contra los ataques de sitios web maliciosos
bm_sz
BBVA
4 horas
Ayuda a protegerse contra los ataques de sitios web maliciosos
ADRUM_BTs
Salesforce Marketing Cloud
Sesión
Requerido para la supervisión del servicio, inherente al SFMC
ADRUM_BT1
Salesforce Marketing Cloud
Sesión
Requerido para la supervisión del servicio, inherente al SFMC
ADRUM_BTa
Salesforce Marketing Cloud
Sesión
Requerido para la supervisión del servicio, inherente al SFMC
ADRUM_BT
Salesforce Marketing Cloud
Sesión
Requerido para la supervisión del servicio, inherente al SFMC
xt_0d95e
Salesforce Marketing Cloud
Sesión
Recordar las preferencias del usuario (si las hay)
__s9744cdb192d044faa1bf201d29fafd1e
Salesforce Marketing Cloud
Sesión
Recordar las preferencias del usuario (si las hay)
wpml_browser_redirect_test
WPML
Sesión
Traducción de textos del portal
wp-wpml_current_language
WPML
24 horas
Traducción de textos del portal
Permiten medir, de forma anónima, el número de visitas o la actividad. Gracias a ellas podemos mejorar constantemente tu experiencia de navegación.
Dispones de una mejora continua en la experiencia de navegación.
Con tu selección no podemos ofrecerte una mejora continua en la experiencia de navegación.
Denominación
Titular
Duración
Finalidad
AMCV_***
Adobe Analytics
Sesión
ID de visitante único que se usan en las soluciones de Marketing Cloud
AMCVS_***
Adobe Analytics
2 años
ID de visitante único que se usan en las soluciones de Marketing Cloud
demdex (safari)
Adobe Analytics
180 días
Crear y almacenar identificadores únicos y persistentes
sessionID
Adobe Analytics
Sesión
Cookie interna de Launch usada para identificar al usuario
gpv_URL
Adobe Analytics
Sesión
plugin Adobe Analytics: getPreviousValue Capturar el valor de una determinada variable en la siguiente vista de página, en este caso la prop1
gpv_level1
Adobe Analytics
Sesión
Cookie utilizada para almacenar el levl1 del DataLayer de la página anterior.
gpv_pageIntent
Adobe Analytics
Sesión
Cookie utilizada para almacenar el pageIntent de la página anterior.
gpv_pageName
Adobe Analytics
Sesión
Cookie utilizada para almacenar el pagename de la página anterior.
aocs
Adobe Analytics
Sesión
Cookie que almacena los primeros valores recogidos al inicio de un proceso.
TTC
Adobe Analytics
Sesión
Cookie usada para almacenar el tiempo transcurrido entre el evento App Page Visit y App Completed.
TTCL
Adobe Analytics
Sesión
Cookie usada para almacenar el tiempo transcurrido entre el evento LogIn y App Completed.
s_cc
Adobe Analytics
Sesión
Determinar si las cookies están activas
s_hc
Adobe Analytics
Sesión
Cookie usada por Adobe con propositos de analítica.
s_ht
Adobe Analytics
Sesión
Cookie usada por Adobe con propositos de analítica.
s_nr
Adobe Analytics
2 años
Determinar el número de visitas de usuario
s_ppv
Adobe Analytics
Persistente
plugin Adobe Analytics: getPercentPageViewed Determinar el procentaje de página que visualiza un usuario
s_sq
Adobe Analytics
Sesión
Funcionalidades ClickMap/ActivityMap
s_tp
Adobe Analytics
Sesión
Cookie usada por Adobe con propositos de analítica.
s_visit
Adobe Analytics
2 años
Cookie usada por Adobe para saber cunado una sesión se ha iniciado.
Permiten que la publicidad que te mostramos sea personalizada y relevante para ti. Gracias a estas cookies no verás anuncios que no te interesen.
Dispones de una publicidad adaptada a ti y a tus preferencias.
Con tu selección pierdes la personalización de la publicidad, solo verás anuncios genéricos.
Denominación
Titular
Duración
Finalidad
OT2
VersaTag
90 días
Cookie de VersaTag usada para almacenar un id de usuario y el numero de visitas del usuario.
u2
VersaTag
90 días
Cookie de VersaTag en la que se almacena el ID del usuario
TargetingInfo 2
MediaMind
1 año
Cookie que sirve para asignar un número unico random que genera MediaMind.
Estas cookies están relacionadas con características generales como, por ejemplo, el navegador que utilizas.
Dispones de una experiencia y contenidos personalizados.
Con tu selección no podemos ofrecerte una navegación y contenidos personalizados.
Denominación
Titular
Duración
Finalidad
mbox
Adobe Target
9 días
Cookie usada por Adobe Target para hacer test de personalizacion de experencia del usuario.
×
Parece que estás navegando desde México, así que vamos a mostrarte el contenido personalizado para tu localización. Cambiar
Parece que estás navegando desde España, así que vamos a mostrarte el contenido personalizado para tu localización. Cambiar
Selecciona el país
Para poder acceder al área privada y sandbox correspondiente, selecciona el país de las APIs que quieres utilizar.
×
×
×
Preferencias de Navegación
Elige el país del que quieres que te mostremos su contenido por defecto.