El mundo de Big Data evoluciona rápido. Siempre aparecen nuevas tecnologías que prometen gestionar y analizar grandes volúmenes de datos de una forma más rápida, más escalable y con unos coste de implementación y mantenimiento más baratos. Lo cierto es que de todas esas novedades, Apache Spark, la plataforma de computación distribuida de código abierto, es la más reseñable porque aporta valor añadido con respecto a sus predecesores.
Existen muchas características que hacen de Spark una plataforma especial, pero podríamos englobarlas en cinco aspectos importantes: es una plataforma de código abierto con una comunidad muy activa; es una herramienta rápida; unificada; dispone de una consola interactiva cómoda para los desarrolladores; y también tiene una API para trabajar con los grandes datos.
1. Una plataforma de código abierto con una comunidad activa
Una de las propiedades más interesantes de una solución de código abierto es la actividad de su comunidad. Es la comunidad de desarrolladores la que mejora las características de la plataforma, y ayuda al resto de programadores a implementar soluciones o resolver problemas.
La de Apache Spark es una comunidad cada vez más activa: en septiembre de 2013 había más de 113.000 líneas de código; un año después, se superaban las 296.000; y este septiembre de 2015, el volumen de líneas de código ya marca un récord: 620.300.
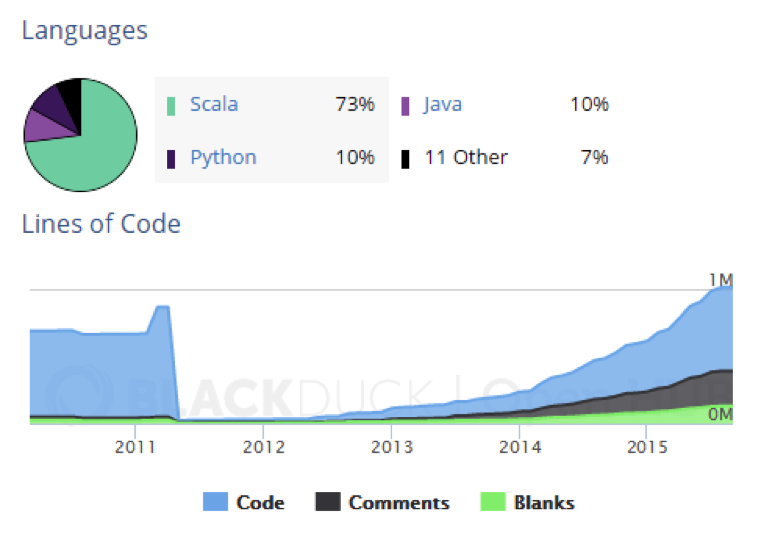
Además, la comunidad no deja de crecer en el número de programadores desde junio de 2012. En esa fecha, se dieron de alta cuatro contribuyentes nuevos. En junio de 2015, tres años después, ese número fue de 128. En el último mes del que se tienen datos, julio de 2015, se sumaron al proyecto 137.
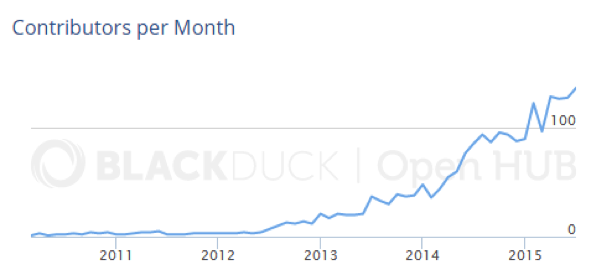
2. Una plataforma rápida
Una de las primeras circunstancias que sorprenden de Spark es que, para ser una plataforma de código abierto, su velocidad es enorme, muy por encima de algunas soluciones propietario. ¿Por qué es tan rápida? Apache Spark permite a los programadores realizar operaciones sobre un gran volumen de datos en clústeres de forma rápida y con tolerancia a fallos. Cuando tenemos que manejar algoritmos, trabajar en memoria y no en disco mejora el rendimiento.
Así, en materia de aprendizaje automático (machine learning), Spark ofrece unos tiempos de cálculo en memoria mucho más rápidos que cualquier otra plataforma. El almacenamiento de los datos en la memoria caché hace que la iteración de los algoritmos de machine learning con los datos sea más eficiente. Las transformaciones que se van produciendo de esos datos también se almacenan en memoria, sin tener que acceder dentro del disco.
En su página web hay una prueba de competencia que muestra el rendimiento de Spark con respecto a MapReduce: de 10 a 100 veces más rápida.
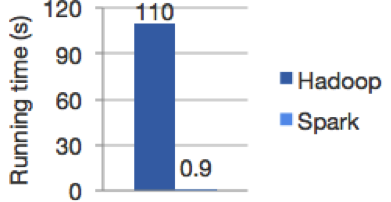
En ese procesamiento de datos en memoria, el equipo de desarrolladores dispone de la flexibilidad suficiente para escoger qué datos quedan en memoria y cuáles pueden volcarse al disco duro porque no son necesarios en ese momento. Eso libera mucho el procesamiento, aumentando su eficacia.
3. Una plataforma unificada para gestionar datos
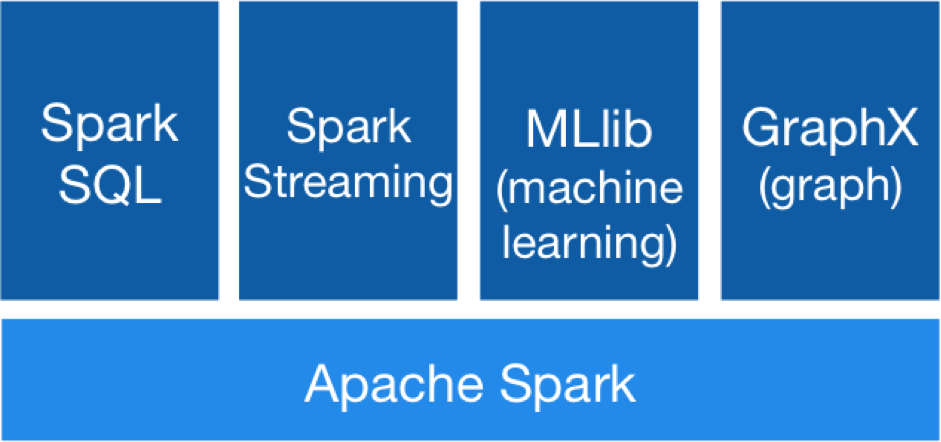
Es una de las características más reconocibles de Apache Spark. Es una plataforma de plataformas. Un ‘todo en uno’ que agiliza mucho el funcionamiento y el mantenimiento de sus soluciones. Combina:
– Spark SQL: permite la consulta de datos estructurados utilizando lenguaje SQL o una API, que se puede usar con Java, Scala, Python o R.
– Spark Streaming: mientras MapReduce solo procesa datos en lotes, Spark tiene la posibilidad de gestionar grandes datos en tiempo real. Esto facilita que los datos se analicen según van entrando, sin tiempo de latencia y a través de un proceso de gestión en continuo movimiento.
– MLlib (Machine Learning): esta herramienta contiene algoritmos que dotan a Apache Spark de muchas utilidades, como la regresión logística y máquinas de vectores de soporte (SVM); modelos de árbol de regresión bayesiana; técnicas de mínimos cuadrados; modelos de mezclas gausianas; análisis de conglomerados de K medias; asignación latente de Dirichlet (LDA); descomposición en valores singulares (SVD); análisis de componentes principales (ACP); regresión lineal; regresión isotónica…
– GraphX: es un framework de procesamiento gráfico. Proporciona una API para la elaboración de grafos con los datos. Primero fue un proyecto separado de AMPLab y Databricks de la Universidad de Berkeley, como Spark, pero posteriormente se unió a la Fundación de Software Apache.
4. Consola interactiva
Una de las ventajas de trabajar con Spark son las consolas interactivas que tiene para dos de los lenguajes con los que se puede programar, Scala (que se ejecuta en una máquina virtual Java- JVM) y Python. Estas consolas permiten analizar los datos de forma interactiva, con la conexión a los clústeres.
Por poner un ejemplo, los desarrolladores en Python pueden y suelen utilizar IPython para ejecutar la API de Spark en Python (PySpark). IPython es un sistema para crear documentos ejecutables. Con IPython se puede integrar texto con formato (mediante el lenguaje de marcado Markdown), código ejecutable en Python, fórmulas matemáticas con LaTeX y gráficos y visualizaciones con la librería en Python matplotlib.
5. Una gran API para trabajar con los datos
Apache Spark tiene APIs nativas para los lenguajes de programación Scala, Python y Java. Este conjunto de APIs facilita a los programadores el desarrollo de aplicaciones en estas sintaxis, que se puedan ejecutar en la plataforma de código abierto. Las APIs posibilitan interactuar con los datos de:
– El Sistema de Archivos de Hadoop (HDFS).
– La base de datos NoSQL de código abierto HBase.
– La base de datos NoSQL de código abierto Apache Cassandra.
Las APIs sirven para realizar dos tipos de operaciones sobre los datos:
– Transformar un grupo de datos.
– Aplicar operaciones sobre los datos para obtener un resultado.
Síguenos en @BBVAAPIMarket









